


4 Schritte, wie man Kundendaten für eine erfolgreiche Personalisierung nutzt

Frank steht auf Schnäppchen. Wenn Frank neue Schuhe braucht, geht er in den Laden und sucht nach dem günstigsten Angebot. Seine Freundin Lisa hingegen ist sehr modebewusst und möchte stets die neusten Trends tragen. Die Verkäuferin erkennt durch das Gespräch mit Frank und Lisa die unterschiedlichen Bedürfnisse und berät beide individuell zu passenden Produkten. Zufrieden verlässt Frank mit dem Schnäppchen der Woche das Geschäft, während Lisa stolz die neusten Sneaker an den Füßen trägt.
Was im Stationärhandel einfach klingt, ist in der E-Commerce-Welt nur schwer möglich. Man weiß nicht, wer da gerade den Onlineshop betritt und welche Bedürfnisse er hat. Wüssten wir, dass wir es gerade mit Frank und Lisa zu tun haben, würden wir diese beiden Kundentypen doch sehr unterschiedlich auf der Website ansprechen.
Was, wenn ein Onlineshop das auch könnte? Wie schaffen wir es in der digitalen Welt, unterschiedliche Kundentypen zu identifizieren, um dem Ziel der personalisierten Ansprache im Onlineshop ein Stück näher zu kommen?

Personalisierung und Daten gehören zusammen.
Für gute Beratung braucht es zunächst eine Vorstellung über die Bedürfnisse der Zielgruppe. Die meisten Unternehmen starten mit einer qualitativen Beschreibung ihrer Kunden. Dabei fließen subjektive Annahmen zu deren Persönlichkeit ein. Das Ergebnis sind deskriptive Kundenprofile, z.B. für Kundentypen wie Frank und Lisa. Dies ist ein erster, sehr wichtiger Schritt, um die eigenen Kunden zu verstehen.
Aber wie nutzen wir die qualitativen Beschreibungen, um Frank und Lisa im Onlineshop zu erkennen? An diesem Punkt hakt es oft und man steht vor dem Problem, wie man die Ergebnisse mit den gesammelten Daten zusammenbringen soll.
Bei jedem Besuch im Onlineshop hinterlässt der Besucher Spuren, die eine Menge über seine Vorlieben und das individuelle Verhalten verraten. Die große Herausforderung besteht darin, diese Daten nutzbar zu machen, um Kunden in den Daten zu identifizieren. Erst dann können wir ihnen passende personalisierte Inhalte ausspielen, z.B. durch eine stärkere Preiskommunikation oder mit dem Fokus auf Trends und Neuheiten. Damit wird die Website zu einem echten Berater, der Bedürfnisse analysiert und versteht.
Personalisierung und Daten gehören zusammen. Nur durch die Kombination von Daten zur Messung der Kundeneigenschaften und qualitativer Kundenprofile erhalten wir ein umfassendes Verständnis der eigenen Kunden und können so Maßnahmen zur Personalisierung erfolgreich umsetzen.
Die Clusteranalyse zur quantitativen Beschreibung von Zielgruppen
Franks und Lisas unterschiedliche Präferenzen werden durch die gesammelten Daten zu ihrem Verhalten im Onlineshop messbar. Während Frank oft preisreduzierte Artikel kauft, ist Lisa eher in der Kategorie der Neuheiten und Trends unterwegs. Die Clusteranalyse nutzt diese Daten, um Kunden aufgrund ihrer individuellen Eigenschaften in sogenannte Kundencluster einzuteilen.

1. Qualitative Zielgruppenbeschreibung
Der erste Schritt sollte immer darin bestehen, die unterschiedlichen Kundentypen einzugrenzen. Eine qualitative Zielgruppenbeschreibung hilft dabei, herauszufinden, mit wem wir es eigentlich auf der Website zu tun haben könnten.
Auch wenn sich dadurch im ersten Schritt „nur“ beschreibende Merkmale der Zielgruppe ergeben, sind diese doch extrem wertvoll. Sie dienen dazu, Erkenntnisse zu generieren, in welchen Eigenschaften sich Kundentypen unterscheiden können und was ihnen wichtig ist.
Das Ergebnis der qualitativen Zielgruppenbeschreibung sollte darin bestehen, grobe Cluster von Kunden zu definieren und eine Liste von Attributen zu erstellen, mit denen diese messbar gemacht werden können. Im Fall von Lisa kann eine Zielgruppenbeschreibung folgendermaßen aussehen:

2. Sammeln relevanter Kundendaten
Im nächsten Schritt werden die Daten bereitgestellt. Hier können unterschiedlichste Datenquellen herangezogen werden, wie z.B. das Webanalyse-Tool, CRM-Daten, Mouse Tracking oder Daten aus dem Backend.
Ganz konkret bedeutet das: Man sollte sich eine ausreichend große Datenmenge von Kunden zusammenstellen und darauf achten, dass man einen repräsentativen Zeitraum wählt. Schwierig wird es zum Beispiel, wenn man einen Zeitraum wählt, in dem viele Sale-Kampagnen gelaufen sind, da sich hier das Verhalten der Kunden signifikant gegenüber dem Rest des Jahres ändern kann. Zudem sollte man die jeweilige Time to Purchase im eigenen Onlineshop berücksichtigen. Es empfiehlt sich, mindestens einen Zeitraum von drei Monaten zu wählen. Die Daten zum Verhalten der Kunden sollten diejenigen Kundeneigenschaften sein, in denen man signifikante Unterschiede im Verhalten erwartet, da es sonst schnell unübersichtlich wird.
Mögliche Attribute können sein:
- Geschlecht
- Alter
- Neu-/Bestandskunde
- Kategorien, in denen jemand kauft
- Besuchte Seiten
- Warenkorbwert
- Conversion Rate
- Traffic-Quelle
- Device
- Daten zum Klickverhalten
- Retourenquote
- Geolocation
- etc.
Kommen wir zurück zu Frank und Lisa. Frank macht seine Kaufentscheidung in der Regel vom Preis abhängig. Er gilt als treuer Kunde, der regelmäßig über Sale-Kampagnen auf die Seite kommt und gezielt nach dem besten Schnäppchen sucht. Lisa hingegen stöbert im Sortiment und interessiert sich für die neusten Produkte, kauft jedoch unregelmäßig und retouniert oft.
All das sind Annahmen zum Verhalten von Frank und Lisa, deren Validität mit Hilfe der richtigen Daten gemessen und überprüft werden können. Als Grundlage für die Clusteranalyse dient eine Matrix, in der die relevanten Daten gesammelt werden:

3. Clusteranalyse der Kundeneigenschaften
Das Verfahren der Clusteranalyse basiert auf einem einfachen Algorithmus, der es erlaubt, mit Hilfe von gemessenen Kundeneigenschaften Gruppen zu identifizieren, die in sich ein möglichst ähnliches Verhalten aufweisen und sich untereinander möglichst stark unterscheiden. Das konkrete Vorgehen hängt davon ab, wie viele Annahmen zu den eigenen Kunden mit einfließen sollen und wie komplex man die Analyse aufsetzen möchte.
Im Folgenden werden zwei Vorgehensweisen skizziert, die sich in ihrem Komplexitäts- und Erkenntnisgrad unterscheiden:
A. Die eindimensionale Clusteranalyse
Mit diesem Verfahren lassen sich durch einfache Analysen bereits wichtige Erkenntnisse gewinnen. Hat man eine Vorstellung davon, nach welchem Kriterium man die Kundenbasis segmentieren möchte, bietet es sich an, mit einer einfachen Unterteilung zu starten.
Bei Frank und Lisa liegt es nahe, dass sich die Kategorien, in denen sie kaufen, voneinander unterscheiden. Durch eine gezielte Analyse des Kundenverhaltens in den Kategorien lassen sich Kundengruppen definieren und voneinander abgrenzen. Das Attribut, mit dem die Clusteranalyse durchgeführt wird, sind hier also die unterschiedlichen Kategorien des Onlineshops, sowie die zugehörigen Kundendaten aus dem Web Analytics-System. Die gesammelten Daten lassen sich den einzelnen Kategorien zuordnen, sodass man eine datengetriebene Beschreibung der Kundengruppen aus den Kategorien erhält. Diese kann im Fall von Lisa und Frank folgendermaßen aussehen:
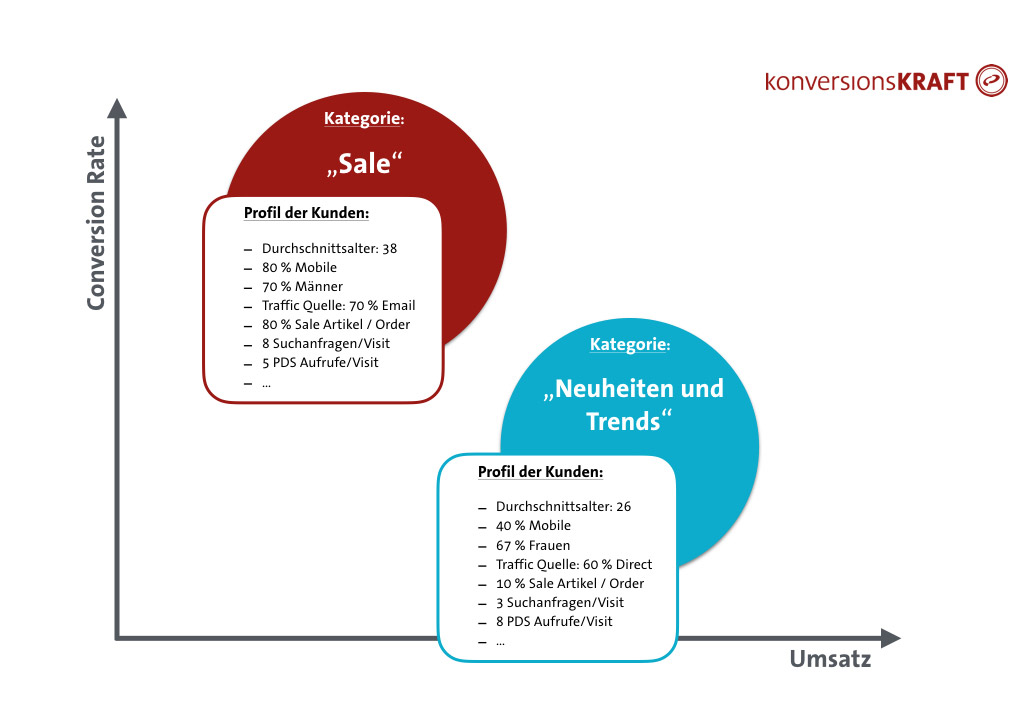
Vorteile der eindimensionalen Analyse:
- Einfach
- Schnelle Ergebnisse, die für erste Personalisierungsmaßnahmen genutzt werden können
Nachteile der eindimensionalen Analyse:
- Basiert auf subjektiven Annahmen und persönlichen Meinungen
- Ergebnisse sind davon abhängig, nach welchem Kriterium man die Daten clustert
- Andere Attribute, deren Mehrwert für eine Personalisierung vielleicht noch höher wäre, werden übersehen
- Das Clustering auf Basis eines Kriteriums liefert keine trennscharfen Kundentypen

B. Die mehrdimensionale Clusteranalyse
Aufgrund dieser Nachteile bietet sich ein zweiter Ansatz an, um Kundeneigenschaften zu clustern. Bei der mehrdimensionalen Clusteranalyse wird vorab kein festes Kriterium bestimmt, nach dem die Daten gruppiert werden sollen. Hier werden die relevanten Unterscheidungsmerkmale aus dem Modell heraus bestimmt. In diesem Fall verwendet der Algorithmus alle Kundeneigenschaften aus der Datenmatrix, um selber die optimale Anzahl von Kundengruppen zu bestimmen. Die gebildeten Gruppen bestehen aus Kunden, die in den Eigenschaften sehr ähnlich sind, während sie sich von einer anderen Kundengruppe unterscheiden.
Das klingt erstmal komplex, aber mit ein wenig Statistik-Kenntnissen kann man diese Methode einfach implementieren und sogar in Excel laufen lassen. Wer sich mit anderen Statistik Tools, wie SPSS oder R auskennt: Auch hier ist die Clusteranalyse einfach möglich. Die gebildeten Kundencluster lassen sich dann mit Hilfe von deskriptiven Statistiken wie Mittelwerten, Streuung und Gruppengröße in ihren Eigenschaften beschreiben und voneinander abgrenzen.
In folgenden Fällen ist die mehrdimensionale Analyse zu empfehlen:
- Man hat keine Annahmen, in welchen Eigenschaften sich die Kunden besonders stark unterscheiden,
- man möchte herausfinden, wie viele Kundentypen es eigentlich gibt, oder
- wenn der eindimensionale Ansatz keine verwertbaren Ergebnisse gebracht hat.
Nachdem man mit Hilfe dieses Ansatzes die Datencluster identifiziert hat, sollte man versuchen, diese mit den qualitativen Kundenprofilen zu verbinden. Dabei ist es nicht selten, dass die Daten ein anderes Bild der Kunden liefern als man ursprünglich in den qualitativen Zielgruppenbeschreibungen festgelegt hat. Das ist auch völlig in Ordnung. Die Ergebnisse der Clusteranalyse dienen dazu, die Annahmen zu verfeinern oder sogar zu revidieren. Vielleicht lag man in seiner eigenen Meinung zum Verhalten der eigenen Kunden nicht ganz richtig. Das zeigen die Daten.
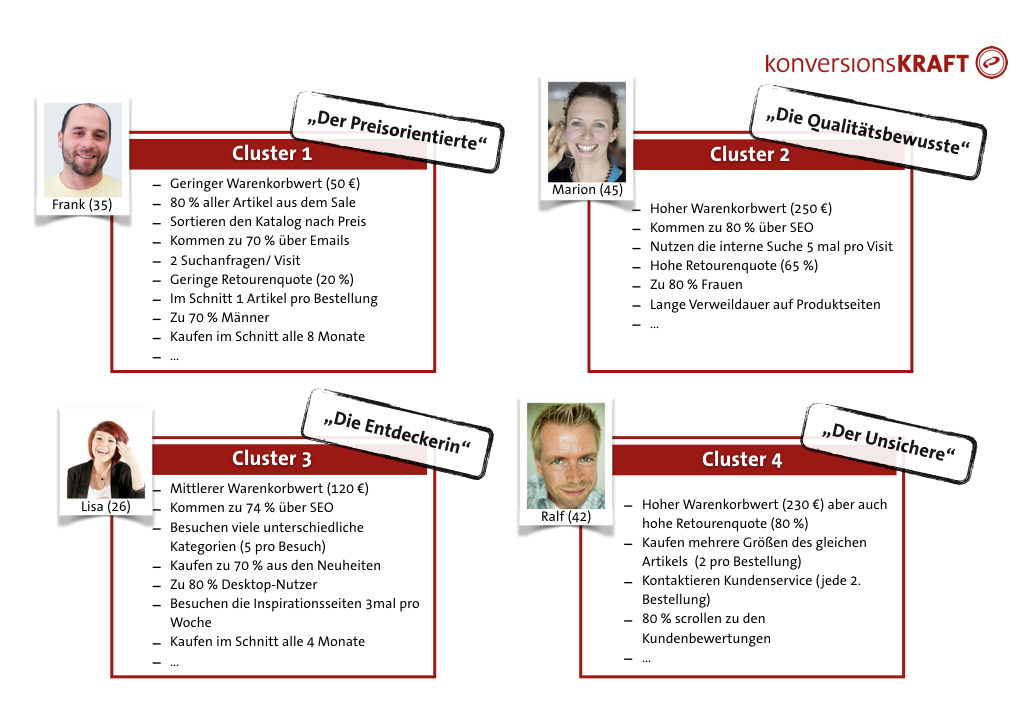
So kann es durchaus sein, dass man herausfindet, dass Frank – der Preisorientierte -und Lisa – die Entdeckerin – sich in anderen Eigenschaften voneinander unterscheiden, als man ursprünglich angenommen hat. Zudem können weitere interessante Kundensegmente existieren, die man bei der eindimensionalen Analyse nicht identifiziert hätte.
4. Ausspielung der Personalisierung / A/B-Testing
Im letzten Schritt geht es an die personalisierte Ausspielung von Inhalten, die zu den gemessenen Eigenschaften der Zielgruppen-Cluster passen. Dabei empfiehlt es sich, mit der oder den relevantesten Zielgruppen aus der Clusteranalyse zu starten.
Wichtig ist, dass das passende Personalisierungskonzept auch an die richtige Kundengruppe ausgespielt wird. Für Frank scheint es wichtig, über regelmäßige Sale-Aktionen informiert zu sein. Durch eine personalisierte Preiskommunikation, das Herausstellen der Ersparnis sowie der passenden Ansprache („bester Deal“) können seine Bedürfnisse besser abgedeckt werden.
Für Lisa hingegen ist es wichtig, stets mit den neuen Trends zu gehen. Ein größerer Fokus auf Inspirations- und Fashionthemen mit passender Ansprache passt zu ihren Wünschen.
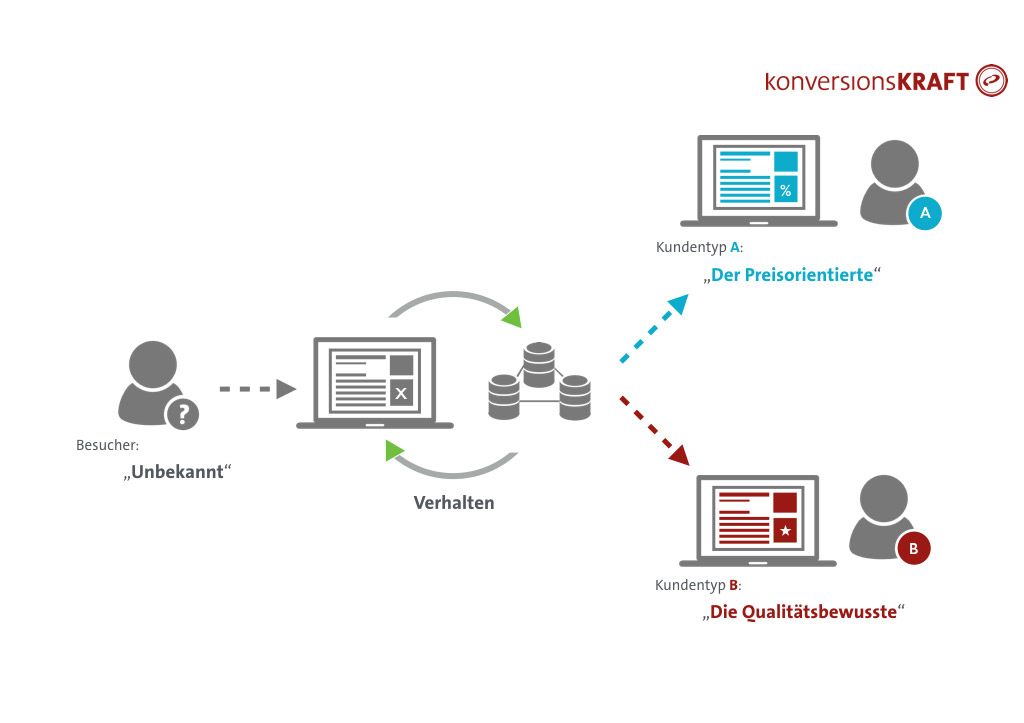
Anhand ihrer gemessen Eigenschaften lassen sich Kunden, die den Onlineshop besuchen, in das entsprechende Cluster einordnen. Die Zuordnung und Ausspielung kann über ein Personalisierungstool erfolgen, ist aber auch mit gängigen Testing Tools möglich. Hier lassen sich die Kundentypen aus der Clusteranalyse über gezieltes Targeting definieren. Besucht ein Kunde nun den Onlineshop, wird anhand seiner Eigenschaften (Daten aus dem Tracking) geprüft, in welches der Kundencluster er gehört und er erhält die entsprechende persönliche Ansprache.
Fazit
Durch das Zusammenspiel aus qualitativen und quantitativen Analysen kann man zielgruppenspezifische Personalisierungskonzepte entwickeln, ohne dass man gleich mit hoher Komplexität starten muss. Dabei sollte man stets die entwickelten Konzepte mit Hilfe von A/B-Tests validieren, da dieser Ansatz auf einer Reihe von subjektiven Annahmen beruht. Zeigen sich in den Tests keine signifikanten Uplifts, so kann das zum einen am Konzept liegen, aber auch an der Definition der Cluster. Im Endeffekt würde das bedeuten, dass man seine Clusterdefinition verwerfen und wiederholen müsste. Im zweiten Teil des Artikels soll es deswegen darum gehen, wie man auf Basis von A/B-Tests unterschiedliche Zielgruppen definieren kann, um diese mit personalisierten Konzepten zielgenauer anzusprechen. Stay tuned!











