


Konfidenz sollte man kennen. (Grundlagen zur Statistik beim A/B Testing)

Täglich werden Case Studies veröffentlich, in denen von teilweise erstaunlich hohen Uplifts die Rede ist. Doch wie belastbar sind diese Zahlen wirklich? Die Grafiken und Angaben, die in der Testing-Software zu sehen sind, mögen auf den ersten Blick recht einfach und plausibel wirken – bei näherer Betrachtung kommen dann aber die ersten Fragen:
„In der Testing-Software wird ein Uplift von 4% bei einer CTBO von 92% angezeigt. Heißt das nun, dass mit 92% Prozent Wahrscheinlichkeit der Uplift 4% ist?“
Jeder, der ohne eine Statistikvorlesung im Lebenslauf beginnt, sich in der Praxis mit Testing zu befassen, wird sich über kurz oder lang die gleichen Fragen stellen und auch mit Missverständnissen bei der Interpretation der Testergebnisse konfrontiert werden. Auch die Frage, wie lange ein Test laufen sollte bzw. wann er gestoppt werden kann, wird gerne diskutiert. Daher möchte ich in diesem Blogpost versuchen, das für die Praxis im Testing relevante Wissen verständlich und einfach und ganz ohne Formeln zusammenzufassen.
Befasst man sich näher mit dem Thema und hinterfragt die angezeigten Werte, sieht man sich schnell mit den zugrunde liegenden statistischen Formeln, Annahmen und Methoden konfrontiert. Hinzu kommt, dass die Anzeige je nach verwendeter Software unterschiedlich ist und daher die Werte nicht direkt miteinander verglichen werden können. Es wird noch komplizierter, wenn nicht mit einer einfachen Conversion-Rate, sondern mit Revenue oder Engagement-Score gerechnet wird.
Du solltest aufgrund dieser Begriffe jedoch keine Angst vor der Kultur des Experimentierens haben! Gerne kannst du dich für unser Growth Ambassador Programm bewerben, um dich mit anderen Expert:innen unserer Community in regelmäßigen Meetups über A/B-Testing auszutauschen. Es wartet zudem ein sehr interessanter Videokurs auf dich, der dir beibringt, wie du erfolgreich experimentierst.
Aber zuvor noch einmal zurück zu den Grundlagen:
Was sollen die Zahlen uns überhaupt sagen?
Die Statistik beim Testing dient dem Ziel, aus einer kleinen Menge von „Samples“ – also für uns z.B. aus den einzelnen Nutzersitzungen, in denen eine Conversion entweder stattgefunden hat – oder eben nicht – auf die „echten“ Werte zu schließen. Daraus soll eine Zukunftsprognose darüber abgeleitet werden, wie denn die Varianten, die in den Test geschickt wurden, weiterhin „performen“ werden und mit welcher Variante unser Auftraggeber das meiste Geld verdienen kann.
Dabei müssen wir uns allerdings stets bewusst machen, dass Formeln und Software die reale Welt stark vereinfachen müssen, um sie überhaupt abzubilden.
Die erste und gravierendste Annahme ist, dass der Test überhaupt ein sinnvolles Experiment darstellt, auf dessen Basis eine Zukunftsprognose abgegeben werden kann. Bereits dies ist ein häufiger Fallstrick. Wir setzen nämlich voraus, dass die Conversion-Rate jeder einzelnen Variante im Durchschnitt nach dem Testzeitraum die gleiche ist wie während des Testzeitraums. Dass sie sich auf einen Durchschnittswert „einpendelt“. In der Praxis ist diese aber vielen Einflüssen unterworfen. Saisonale Schwankungen, Sportereignisse, langfristige Trends durch sich stetig ändernde Mindsets der Nutzer, die neue TV-Kampagne des Wettbewerbers, sich ändernde Endgeräte oder der frisch versendete neue Katalog sind nur einige Beispiele dafür.
Konfidenzniveau und Konfidenzintervall
Ein Test liefert eine Aussage über ein Intervall, in dem die Conversion-Rate wahrscheinlich liegt. Die Aussage wird um so präziser, je mehr Samples die Stichprobe umfasst – d.h. das Intervall wird kleiner.
Die Aussage bezüglich einer einzigen Variante kann folgendermaßen formuliert werden:
„Auf Grundlage der bereits gemessenen Werte liegt die Conversion-Rate mit 95% Wahrscheinlichkeit zwischen 5,5 und 7,5%.“
Dabei wird „95%“ als das Konfidenzniveau bezeichnet. Dieses ist in unterschiedlichen Testing-Tools auf unterschiedliche Werte voreingestellt. Somit können sich die Angaben unterschiedlicher Testing-Tools schon alleine dadurch unterscheiden, wie „optimistisch“ sie mit dem Konfidenzniveau umgehen.
Mehr dazu kann man im folgenden Wikipedia-Artikel nachlesen:
http://de.wikipedia.org/wiki/Konfidenzintervall
Die statistischen Formeln basieren auf der Annahme, dass die Mittelwerte von Testreihen annähernd normalverteilt um den tatsächlichen Mittelwert sind. Das ist insbesondere bei sehr niedrigen Conversionraten eventuell gar nicht der Fall – die reale Verteilung könnte eher „schief“ sein. Viele Testingtools rechnen zudem direkt mit den Formeln der Normalverteilungskurve und gehen davon aus, dass der Mittelwert aus der Testreihe auch dem tatsächlichen Mittelwert enspricht – bei einer geringen Anzahl von Conversions führt dies dazu, dass das Konfidenzintervall kleiner ausgewiesen wird, als es tatsächlich ist.
Das alles bedeutet jedoch nicht, dass die Ergebnisse der Testing-Tools völlig unbrauchbar sind – für die Conversion-Optimierung ist das letzte Prozent Konfidenzniveau nicht wirklich entscheidend, man sollte nur nicht den Fehler machen, die Ergebnisse zu optimistisch zu interpretieren!
Uplift
Der Uplift wird üblicherweise berechnet, indem die Mittelwerte zweier Varianten ins Verhältnis gesetzt werden. Diese Zahl ist allerdings mit noch einem höheren Fehler behaftet, als die einzelnen Conversion-Rates – eine Aussage über den Uplift lässt sich als Intervall (von-bis) bei einem gewissen Konfidenzniveau ausdrücken. Vereinfacht kann man für den maximalen Uplift die beiden weiter auseinander liegenden Conversionraten-Intervallgrenzen ins Verhältnis setzen, für den minimalen Uplift die beiden eng beieinander liegenden Werte.
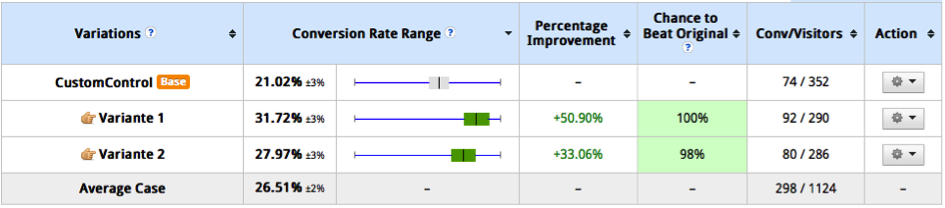
Übrigens: Ich erbitte bei der Gelegenheit sinnvolle Vorschläge (auf Deutsch oder Denglisch) für das Gegenteil von Uplift!
Chance to Beat
Je nach Software werden auch die Werte „Chance to Beat Original“ (CTBO), „Chance to Beat Control“ (CTBC) oder „Chance to Beat Baseline“ – was in etwa das gleiche bedeutet – aber teilweise auch die „Chance to Beat All“ (CTBA), die eine andere Bedeutung hat, ausgewiesen.
Für die „CTBC“ wird die Überlappung der Intervalle der betrachteten Variante mit der Kontrollvariante berechnet. Je weniger sie sich überlappen, desto größer die Wahrscheinlichkeit.
Die Aussage ist also bei 95% CTBO:
„Mit 95% Wahrscheinlichkeit ist die Variante irgendwie besser als das Original“ – was schon gegeben ist, wenn der reale Uplift nur minimal über Null liegt.
Eine häufige Fehlinterpretation ist, anzunehmen, dass CTBO die Wahrscheinlichkeit angibt, mit der der angezeigte Uplift (mindstens) erreicht wird, oder der „Konfidenz“ des Uplifts entspricht. Um Wahrscheinlichkeit zu berechnen, mit der ein bestimmter Uplift mindestens erreicht wird, müsste man nämlich nur den „rechten“ Abschnitt der Verteilungskurve heranziehen. Die entsprechenden Berechnungen sind jedoch nicht einfach, und leider sieht keines der mir bekannten Testingtools eine derartige Möglichkeit vor.
Wenn die betrachtete Variante „am verlieren ist“, ist die CTBO kleiner als 50%. Je kleiner die CTBO ist, desto klarer wird, dass es sich um eine Verlierervariante handelt.
Für die „Chance To Beat All“ (CTBA) wird eine entsprechende Berechnung gegen jede andere Variante durchgeführt, die Ergebnisse werden wiederum miteinander verrechnet.
Konfidenz
Einige Tools, beispielsweise Adobe Test&Target, zeigen zusätzlich Konfidenzwerte für den Uplift an. Dieser Wert darf keinesfalls mit der CTBO verwechselt werden. Sie sagt nämlich überhaupt nichts über die Änderung der Conversion-Rate aus oder darüber ob es sich um eine Gewinner- oder Verlierer-Variante handelt. Sie ist vielmehr um so größer, je valider die gezeigten Uplift- oder Verringerungs-Zahlen sind, und kann selbst dann hoch sein, wenn die Variante weder besser, noch schlechter „performt“ als das Original.
Zur Berechnung wird die „Signal-To-Noise-Ratio“ in Anspruch genommen – diese wiederum setzt den ermittelten Unterschied der Varianten ins Verhältnis mit dem Fehler, mit dem die Zahlen behaftet sind.
Aber heute keine Formeln! Wichtig ist nur, dass der Unterschied klar ist!
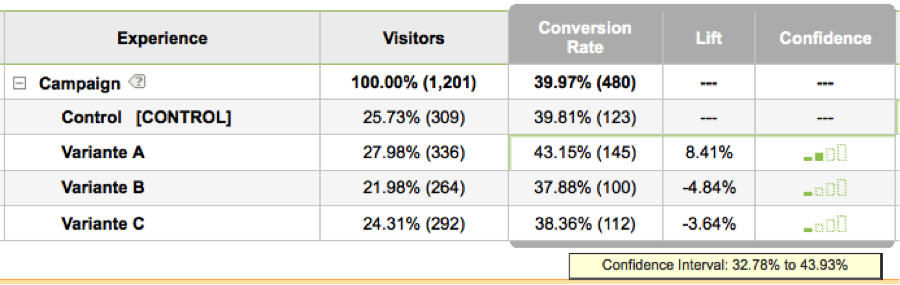
Rechnen mit Revenue oder Score
Ein Experiment, bei dem lediglich eine Conversion Rate ermittelt wird, ist „binomial“ – der Kunde kauft entweder, oder er lässt es bleiben. Ein wenig komplizierter wird es hingegen, wenn andere Metriken ins Spiel kommen, wie z.B. Revenue – für die Optimierung von E-Commerce-Angeboten Pflicht – oder auch ein Engagement Score.
Die Formeln in den Testing-Tools werden hierbei ein klein wenig geringer – das ist für den nächsten Post spannend – die ausgegebenen Werte sind aber im Grunde die gleichen.
Es wird lediglich zusätzlich ein weiterer Wert angegeben: „Revenue per Conversion“ – oder „Average Order Value“. Eine Größe, die durchaus ebenso optimierenswert ist, wie die Conversion-Rate, aber leider oft vernachlässigt wird.
Das Resultat beider Größen ist die „Revenue per Visitor“ – also die Angabe, wieviel durchschnittlich mit einem Besucher (egal, ob er bestellt, oder nicht) verdient wird.
„Conversion Rate“ * „Revenue per Conversion“ = „Revenue per Visitor“
Diese steigt bei steigender Conversion Rate, aber auch bei steigendem durchschnittlichen Bestellwert. Es ist die wirklich wichtige Metrik für einen Shop, die onsite noch ermittelbar ist, ohne Zahlungsausfälle und Retouren zu berücksichtigen.
Die Revenue-basierten Angaben (Uplift, CTBO usw.) werden um so schneller valide, je weniger die Revenues der einzelnen Conversions auseinander liegen. Oder umgekehrt: Wenn man im gleichen Shop Socken und komplette Einbauküchen kaufen kann, und man alle Kunden in den gleichen Test schickt, sollte man davon ausgehen, dass man den Testergebnissen nicht so schnell trauen kann. Da die Software nämlich nach einer Woche Socken und Blusen noch nicht wissen kann, dass morgen ausnahmsweise jemand eine Küche bestellen wird, wird sie brav heute noch ein hohes Konfidenzniveau zeigen, das morgen komplett zunichte ist.
Einige Testing-Tools bieten eine Funktion an, mit der extrem hohe oder auch extrem niedrige Bestellwerte aus der Berechnung eliminiert werden. Sie zählen dann zwar noch als Conversion, aber als Bestellwert wird der Mittelwert der restlichen Bestellungen eingesetzt. Das kann das Ergebnis verfälschen – man optimiert auf ein Mal nur noch für Nutzer mit „normalen“ Warenkörben und nicht für die Küchenkäufer – aber wenn man andererseits das Ziel hat, einen Shop auf den Kauf von Küchen zu optimieren, sollte man vielleicht zunächst nachrechnen, ob man nach einer entsprechenden Segmentierung noch genügend Conversions hat, um den Test valide zu bekommen – ich fürchte, kaum jemand verkauft so viele Einbauküchen online…
Wie lange muss der Test laufen?
Wie lange ein Test laufen muss, hängt von unterschiedlichen Faktoren ab.
Der einfachste Faktor wird von der Software während des Tests permanent berechnet und lässt sich auch mit einem „Test Duration Calculator“ prognostizieren: Die statistische Konfidenz. Diese wird erst erreicht, wenn eine gewisse Anzahl von Conversions vorliegt – abhängig vom „Kontrast“ und der Anzahl der Varianten im Test.
Test duration calculator von Visual Website Optimizer:
http://visualwebsiteoptimizer.com/ab-split-test-duration/
Allerdings gibt es noch einige weitere Faktoren zu beachten:
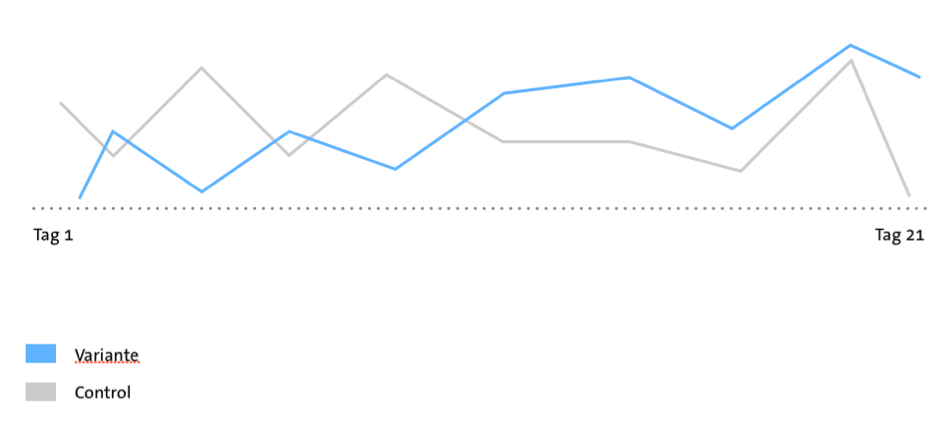
- Ein Test sollte nicht zu kurz laufen, damit die periodischen Schwankungen (zumindest Uhrzeit, Wochentage) abgedeckt sind. Hat man zwei Wochenenden im Test, aber nur eine Woche dazwischen, betont man das Wochende über.
- Ein Test sollte auch nicht zu lange laufen. Wer so wenig Traffic hat, dass zwei Monate nicht ausreichen, sollte über andere Mittel nachdenken.
- Revenue wird i.d.R. weniger schnell valide als Conversion Rate.
- Die äußeren Rahmenbedingungen eines Tests haben oft mehr Einfluss auf die Ergebnisse, als man zunächst erwartet. Wenn ich den gleichen Test im Weihnachtsgeschäft und im Frühjahr starte, kann ich mit Unterschieden rechnen. Eventuell kann ich aus diesen aber interessante Erkenntnisse für das nächste Weihnachtsgeschäft ableiten.
- Wird für den Stopp eines Tests bewusst ein Zeitpunkt gewählt, bei dem eine gewünschte Variante eine besonders hohe oder niedrige CTBO anzeigt, hat man den Test bereits dadurch manipuliert.
- Je früher der Test im Entscheidungsprozess eingreift, desto wahrscheinlicher ist es, dass eine gewisse Zeit verstreichen muss, um Kunden mit längeren Customer Journeys sauber zu erfassen. Wieviel Tage verstreichen im Durchschnitt vom ersten Site-Kontakt zur Conversion?
Sieben vermeidbare Testing-Fallstricke
- Erstens: Achten Sie darauf, dass der Test unter den Bedingungen erfolgt, für die auch optimiert werden soll.
Nur so sind seine Ergebnisse verwertbar. Wenn Sie Werbung für Grillzubehör im November testen, sagt das nichts über deren Wirkung im Juni aus. Läuft ein Test auf der Startseite, nachdem ein Katalog an Bestandskunden versendet wurde, sagt das nichts über die Resultate für Neukunden aus, die über SEA auf dem Shop landen. - Die CTBO garantiert Ihnen keinesfalls den angezeigten Uplift, sondern sagt nur etwas darüber aus, welche Variante überhaupt die bessere ist. Schauen Sie sich das Konfidenzintervall an, um den zu erwartenden Uplift abzuschätzen.
- Verwechseln Sie nicht CTBO mit Konfidenz. Die Konfidenz kann hoch sein, auch wenn der Test ergibt, dass die Varianten sich wenig voneinander unterscheiden.
- Unterschiedliche Tools rechnen mit unterschiedlichen Konfidenzniveaus. – die Resultate lassen sich nur bedingt vergleichen.
- Die Conversion Rate ist meist nicht die wichtigste Metrik, wird aber schneller valide und zeigt daher in vielen Fällen früher Trends an.
- Die Testdauer sollte nicht ausschließlich davon abhängig gemacht werden, welche Konfidenz das Testing-Tool anzeigt. Wenn trotz viel Traffic unerklärliche Schwankungen im zeitlichen Verlauf der Conversion Rates zu sehen sind, könnten äußere Einflüsse schuld sein.
- Will ein Test partout keinen validen Uplift bringen, hat man wohl daneben gelegen. Man sollte nicht ewig warten, sondern lieber abbrechen und andere Varianten ins Rennen schicken.
Und das wichtigste zum Schluss: Stets das Ganze im Auge behalten und das Denken nicht der Software überlassen! In diesem Sinn viel Erfolg beim Testen!
In weiteren Artikeln werde ich demnächst darauf eingehen, wie man die Berechnungen selbst (z.B in Excel) durchführen kann, wenn man z.B. nicht alle Daten zentral in der Testing-Software vorliegen hat – und wo auch dort Fallstricke liegen können.












12 Kommentare
Pablo,
Sehr nützlich und detailliert beschrieben. Vielen Dank
Jan,
Die Tatsache, dass unterschiedliche Varianten verwendet werden und ein einzelner Nutzer durchaus dann auch unterschiedliche Varianten zu Gesicht bekommt, gleichwohl eventuell versucht wird dies zu unterbinden, lässt die Frage aufkommen, ob dann nicht der Test an sich das positive Ergebnis erzeugt und nicht eine einzelne Variante.
Deshalb drängen sich für mich Fragen auf:
Funktioniert die Mischung aller Varianten zusammen nicht besser als die beste Variante allein?
Ist das Kaufverhalten nicht von so vielen Faktoren beeinflusst, dass die Conversion Rate Optimierung mit Testing ohnehin nicht sehr aussagekräftig ist und muss man dann nicht folgerichtig sagen, dass maximal eine Optimierung auf CTR halbwegs eine Aussagekraft mit sich bringt?
Widerspricht sich der Versuch, mit A/B oder MVT das bestmögliche Angebot für die Gesamtheit der Nutzer zu entwickeln, nicht mit der Annahme dass desto mehr Individualität für den einzelnen Nutzer gegeben ist, desto höher auch die Ergebnisse ausfallen?
Das sind meine Fragen zum Testing, die sich für mich bis Heute nicht geklärt haben. Ich bin immer noch auf der Suche nach Jemandem, der mir dies erklären kann. Und wozu brauche ich dann überhaupt eine Testing-Software?
Viele Grüße, Jan
Thorsten Barth,
@Pablo: Danke sehr! Wenn noch Fragen auftreten, sehr gerne!
@Jan: Spannende Fragen! Ich hatte mir schon vorgenommen, demnächst einmal einen eigenen Artikel zu einigen dieser Themen zu schreiben.
Also, zu deinem ersten Punkt. Es gibt bei der Konzeption/dem Setup eines Testszenarios unterschiedliche Möglichkeiten. Zunächst einmal ist wichtig, dass man Varianten (bei einem A/B/n-Test) von Faktoren (bei einem multivariaten Test) unterscheidet – lassen wir dabei aber einmal das gleichzeitige Betreiben mehrerer Tests außen vor.
Das wohl verbreitetste Onsite-Testszenario funktioniert aber gar nicht so, wie du es beschreibst. Man weist jedem Besucher nur ein einziges Mal zu Beginn eine der Varianten zu. Bei einem MVT ist eine Variante eine der Kombinationen der verschiedenen Faktoren. Die zugeordnete Variante behält er aufgrund eines Cookies bei, auch bei wiederholtem Besuch der Website. Er sieht die andere Alternative nie. Die Ergebnisse sagen also etwas darüber aus, welche Variante besser „funktioniert“.
Zum zweiten Punkt. Je weiter „vorne“ man testet, desto mehr kann es natürlich Sinn machen, einem Nutzer unterschiedliche Varianten zu zeigen. Dies betrifft insbesondere Werbemittel. Ausreichend Traffic vorausgesetzt, können sogar Tests Sinn machen, bei denen man Kombinationen aus Werbeschaltungen über mehrere View- und Touchpoints hinweg testet. Beispiel: Beim ersten View Aufmerksamkeit und Relevanz betonen, dann beim dritten Besuch ein zeitlich befristetes Sonderangebot platzieren – oder vielleicht doch schon beim ersten Besuch?
Zusammenfassend kann man wieder nur sagen: Man muss immer vor Testbeginn wissen, was man mit einem Test herausfinden will – und das kann sehr unterschiedlich sein.
Zum dritten Punkt: Selbstverständlich macht es nicht unbedingt Sinn, alle Nutzer über einen Kamm zu scheren. Oder umgekehrt: Es kann sich lohnen, mit Targeting und Personalisierung zu arbeiten. Aber auch dabei sind Analytics und Testing entscheidend, um nicht im Dunkeln zu tappen. Mit Hilfe eines Webanalyse-Systems, oder auch direkt in besser ausgestatteter Testing-Software, ist es möglich, bei einem Test sogar im Nachhinein mit Hilfe von Segmentierung zu untersuchen, ob die Ergebnisse sich für unterschiedliche Nutzergruppen unterscheiden – dabei kann man natürlich nur die Informationen heran ziehen, die man über die Nutzer hat. Wo kam der Klick her? Suchkeyword oder Anzeige? Endgerät/Browser? Geolocation? Wochentag/Uhrzeit? Man kann diese Informationen für die weitere Optimierung auswerten und darauf basierend auch Regeln für Targeting erstellen. Targeting- und Personalisierungsregeln werden also aufgebaut und permanent verfeinert, während Testing und Analytics die Informationen dafür liefern, wie dies optimal passiert.
Ich hoffe, dass das schon ein wenig weiter hilft. Das Thema ist in Wirklichkeit natürlich noch um einiges vielschichtiger.
Gruß
Thorsten
Julian Kleinknecht,
Vielen Dank für diese präzise Erklärung der statistischen Begriffe und die gut verständliche Zusammenfassung! Ich habe noch zwei Anmerkungen / Tipps zur Analyse der gewonnen Daten.
1. Falls man in einem Shop eine große Preisspanne abdeckt und trotzdem an Revenue/Visitor interessiert ist, sollte man seine gesammelten Daten unbedingt im Webanalysetool genauer ansehen. Man könnte sich hier zum Beispiel die “Ausreißer” jeder Testvariante ansehen. Dafür werden mehrere Segmente mit den Bedingungen Gesamtbetrag > X (wobei X zum Beispiel der durchschnittliche Warenkorb + 50% sein könnte) auf die Daten angewendet. Kehrt man dieses Segment nun um, werden diese Ausreißer einfach ausgeschlossen. (Test&Target bietet diese Funktion an (“exclude extreme orders”), leider lässt sich der Werr, was als Ausreißer gilt, nicht manuell festlegen.) Die statistischen Kennzahlen muss man sich jetzt natürlich per Hand bzw. Excel ausrechnen und kann sich nicht mehr einfach aus dem Testingtool ablesen. Test&Target bietet hierfür eine hilfreiche Excel-Tabelle (http://adobe.ly/15Uj45L).
Falls man tatsächlich sowohl Socken als auch Einbauküchen verkauft, sollte man seine gesammelten Daten auf jeden Fall auch nach verschiedenen Produktkategorien segmentieren.
2. Im Abschnitt “Wie lange muss der Test laufen?” wird darauf hingewiesen, dass es einige Zeit dauern kann bis sich der Einfluss der Testvarianten im Testingtool widerspiegelt. Wie lange dieser Zeitraum ist, kann man in der Webanalyse-Software ganz einfach unter beispielsweise “Time to Purchase” (bei Google Analytics im E-Commerce-Bereich) nachschauen.
Thorsten Barth,
@Julian Kleinknecht – vielen Dank für das Feedback und für die wertvollen Ergänzungen! Ich denke, ich werde sowohl Segmentierung, als auch Time to purchase und Themen rund um Testing in Verbindung mit Wissen über die Customer Journey demnächst noch einmal aufgreifen, freue mich schon auf die Diskussion!
Peer Schmid,
Danke für diesen Artikel. Auch wenn er vom Trend zu leicht verdaulichen “5-Punkte-um-garantiert-was-auch-immer-zu-erreichen” anderer Blogs abweicht, ist die gelieferte Substanz doch klasse. Selbst auf die Gefahr hin, mal wieder ein paar Minuten nachdenken zu müssen. Sollte einem aber für belastbare Tests durchaus wert sein.
peter,
Hallo Thorsten Barth,
leider verstehe ich den Satz “Die Aussage wird um so präziser, je mehr Samples die Stichprobe umfasst – d.h. das Intervall wird kleiner.” nicht.
Könntest du diesen bitte erklären?
Was ist mit Samples gemeint? Und was ist damit gemeint, dass das Intervall kleiner wird?
Danke
Thorsten Barth,
@peter – Mit Samples bezeichnet man allgemein die Anzahl von Messungen, die in einem Experiment vorgenommen werden. Bei einem Conversion-Test also die Anzahl der Nutzer, die die Variante sehen und vor die Entscheidung gestellt sind, ob sie kaufen, oder nicht.
Also: Je mehr Unique Visitors im Test gezählt werden, desto aussagekräftiger wird das Ergebnis.
Der Korridor (“Konfidenzintervall”) ergibt sich dadurch, dass die Ergebnisse zufällig “streuen”. Wenn du den gleichen Conversion-Test mehrfach nacheinander durchführst, wirst du immer unterschiedliche Ergebnisse haben. Je mehr Visitors du in jedem Experiment hast, desto weniger stark weichen die Ergebnisse voneinander ab, die Streuung ist geringer. So sinkt umgekehrt auch die Wahrscheinlichkeit, eine Falschaussage zu treffen, mit steigender Visitor-Zahl.
Florian,
Hallo Thorsten,
du sprichst in deinem gelungenen Blogbeitrag das Thema “Rechnen mit Revenues” an. Mich würde in diesem Zusammenhang interessieren, wie man die Stichprobe für kontinuierliche (und eben keine binomialen) Daten ausrechnet? Die meisten (kostenlosen) Stichproben-Rechner gehen bei der Berechnung von einer Rate (Baseline Conversion Rate) und der Margin of Error aus. Hast du irgendwo eine Erklärung/mathematische Formel parat, um Stichproben für Werte wie Revenues auszurechnen?
Vielen Dank und beste Grüße,
Florian
Florian,
Kleine Korrektur: Natürlich nicht die MoE, sondern den gewünschten, minimalen Effekt, den man beobachten möchten.
Steffen Schulz,
Hallo Florian,
ich empfehle dir für die Berechnung von Stichprobengrößen bei metrischen Werten (also wie z. B. Revenue) die Verwendung von gpower. Gpower ist kostenlos und du hast mit dem Tool noch zahlreiche weitere Möglichkeiten.
Schaue es dir einfach mal an 😉
http://www.gpower.hhu.de/
Florian,
Danke für den Tipp, Steffen. Werde ich mal ausprobieren 🙂