
70% deiner A/B-Tests sind “underpowered”: So rockst du die Statistik

Schon wieder ein Test ohne Uplift. Auch dieses Mal kannst du nicht verstehen was schief gelaufen ist? Und wie sollst du das bloß deinem Chef erklären?

Es gibt viele Gründe warum der Uplift eines A/B-Tests ausbleibt:
- Ein Konzept, das an den Bedürfnissen der Zielgruppe vorbei geht
- Eine ungenaue oder gar keine richtige Testhypothese
- Eine unzureichende Qualität im Design. Technische Bugs in der Umsetzung.
- Und so weiter…
In unserem Optimierer-Alltag beobachten wir aber immer wieder ein ganz anderes Problem, das eigentlich nichts mit dem Konzept an sich zu tun hat: Falsche Statistik und Fehler im quantitativen Vorgehen beim A/B Testings führen zu invaliden Test und statistisch insignifikanten Ergebnissen oder unschlüssigen Tests.
Dabei könnte man das eigentlich ganz einfach verhindern, indem man sich an wichtige Grundregeln der Statistik beim A/B Testing hält. Dazu gehört zum Beispiel, bereits vor dem Teststart die benötigte Testdauer zu bestimmen und den Test ausreichend lange laufen zu lassen.
In einer Studie von 115 durchgeführten A/B Tests hat der erfahrene Marketer und Gründer von Analytics-Toolkit.com Georgi Georgiev herausgefunden, dass fast 70% dieser Tests “underpowered” waren (Mehr zum Begriff der Power findest du später im Artikel). Letztendlich bedeutet das, dass mehr als zwei Drittel der Tests eine unzureichende Stichprobengröße hatten und einfach zu früh abgeschaltet wurden um Uplifts valide nachweisen zu können. Diese Tests sind lapidar gesagt, eigentlich für die Tonne.
In diesem Beitrag erfährst du:
- Warum wir A/B-Tests häufig zu früh abbrechen
- Wie du statistische Testpower sicherstellst
- Wie dir das Sample Size Tool hilft, bessere Tests zu starten
Ein typischer A/B-Test Fail aus der Praxis
Was mit einem A/B Test passieren kann, wenn man sich nicht an eine ausreichende Testlaufzeit hält, zeigt folgendes Beispiel:
Angenommen, ein Test läuft auf der Website und die Variante zeigt einen Uplift von 10% auf die Conversion Rate. Die Ergebnisse sind nach zehn Tagen signifikant (Konfidenz >95%) und der Conversion Optimierer möchte den Test abschalten.
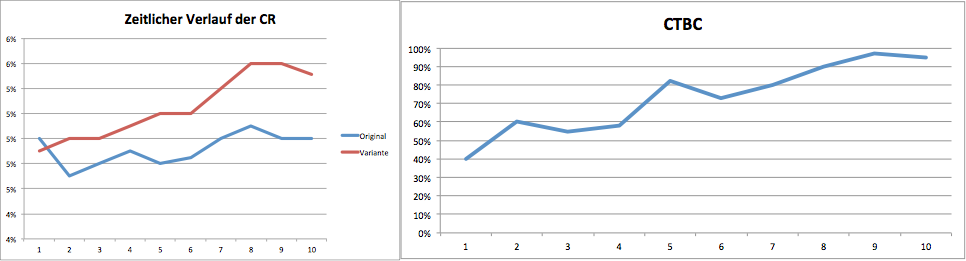
Um ganz sicher zu gehen, hält er nochmal Rücksprache mit der Kollegin aus dem Data Team.
Die Kollegin erinnert ihn daran, dass sie vor dem Teststart ja gemeinsam eine Schätzung der benötigten Dauer durchgeführt haben. Basierend darauf ergab sich eine benötigte Testlaufzeit von 4 Wochen, welche noch längst nicht erreicht ist.
Zudem rät sie davon ab, regelmäßig ins Tool zu schauen bevor diese Grenze erreicht ist. Das erhöht die Fehlerrate enorm, also eine höhere Wahrscheinlichkeit, zufällig einen Uplift zu finden, der in Wahrheit gar nicht existiert und nur zufällig entstanden ist.
Der Conversion Manager willigt ein: “Dann warten wir halt noch ein paar Tage. Was soll sich schon ändern”, denkt er sich….
Ein paar Tage später dann die Ernüchterung. Tatsächlich ist der Effekt immer weiter zurückgegangen und die CTBC („Chance to Beat Control“) auf unter 80% gesunken.
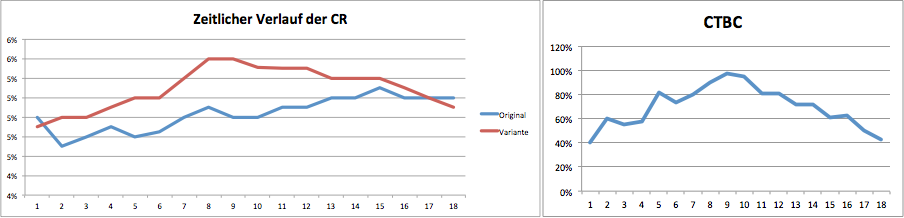
Was ist bei dem Test passiert?
Was wir in der Praxis oft beobachten ist folgendes: Während der Test läuft, wird immer wieder ein Blick ins Tool geworfen ob bereits ein signifikanter Uplift vorliegt. Oft findet dieser Blick statt, bevor die Mindestlaufzeit erreicht wurde oder es mangelt überhaupt an solch einer Schätzung. Sobald ein signifikanter Uplift vorliegt, wird der Test vorzeitig abgeschaltet.
Beim frequentistischen Ansatz zum A/B Testing ist eine wichtige Voraussetzung für valide Ergebnisse, dass man VOR dem Test eine möglichst genaue Schätzung des zu erwartenden Impacts vornimmt und so zu einer Abschätzung der Testlaufzeit findet.
Der regelmäßige Blick in das Tool, vor Ablauf der Testdauer, ist hier grundsätzlich zu vermeiden!
Dadurch erhöht sich die Fehlerwahrscheinlichkeit, zwischendurch einen signifikanten Uplift zu beobachten der rein zufällig entstanden ist. Wenn man dann den Test abschaltet, identifiziert man fälschlicherweise einen Uplift, der aber eigentlich gar keiner ist.
Im Beispiel beruhte der zwischenzeitliche Effekt von 10% und die hohe CTBC nicht auf einem validen Ergebnis mit ausreichend langer Testlaufzeit sondern waren nur eine zufällige, kurzweilige Erscheinung die aber nicht auf eine signifikante Verbesserung der tatsächlichen Conversion Rate schließen ließ.
Anmerkung: Dieser Fall kann natürlich auch andersherum eintreten: Während des Tests beobachtet man zwar einen Uplift, der aber nicht signifikant erst. Erst nach Ablauf der berechneten Testdauer wird das Ergebnis signifikant.
Statistische Testpower: Wie du den Uplift deiner Variante sicher nachweist
Um diese Fehler zu vermeiden, muss man vor dem Teststart eine saubere Abschätzung der benötigten Testlaufzeit durchführen.
Man spricht in diesem Zusammenhang auch von dem Begriff der statistischen Testpower:
Die statistische Power ist die Wahrscheinlichkeit mittels eines Experiments einen Uplift nachweisen zu können, wenn dieser tatsächlich auch existiert. Die Power wird daher auch als Teststärke bezeichnet und gibt an, wie gut ein Test in der Lage ist, einen Unterschied signifikant nachzuweisen.
Wenn die Power eines Tests mindestens 80% beträgt, würde man von einem starken Test sprechen.
Der Wert von 80% ist ein Standardwert, den man für das Power-Level beim A/B Testing verwendet.
Das bedeutet, dass die Wahrscheinlichkeit bei 80% liegt, einen Uplift nachzuweisen, der auch tatsächlich existiert. Im Umkehrschluss besteht also immer noch ein 20 %iges Risiko, dass wir einen Uplift der in Wirklichkeit existiert nicht nachweisen. Vielleicht hast du schon von dem sogenannten „Beta-Fehler” oder einem „False Negative“ gehört (Fehler 2. Art).
Ist die Power des Experiments zu niedrig, laufen wir Gefahr, reelle Uplifts nicht zu finden. Noch schlimmer: Wir schalten ein Experiment ab, weil es einen signifikanten Gewinner ausweist, der in Wirklichkeit gar keiner ist. Wenn so etwas auftritt, spricht man von einem „Alpha-Fehler“ oder einem „False-Positive“ (Fehler 1. Art).
Hier eine kleine Merkhilfe wie du die beiden Fehlerarten beim statistischen Testing unterscheiden kannst:

Berechne die benötigte Testdauer mit unserem Sample Size Tool
Um die benötigte Testdauer zu berechnen, braucht es eine statistische Formel auf Basis der oben beschriebenen Power-Betrachtung.
Wir haben dafür ein Tool entwickelt, das dir hilft, deine Uplifts sicher nachzuweisen und eine bessere Einschätzung für den nachweisbaren Effekt vornehmen zu können.
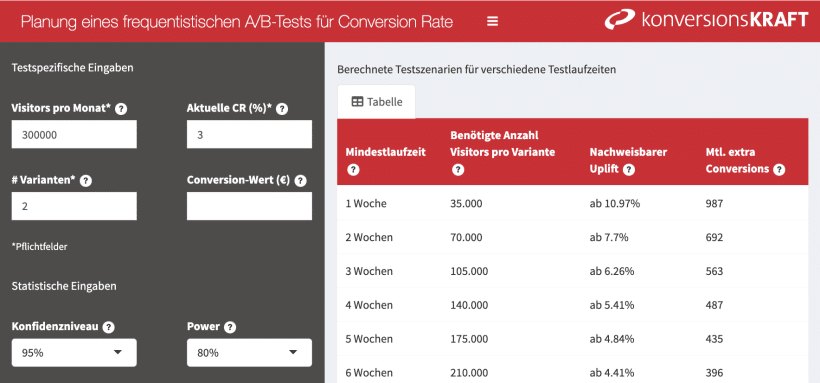
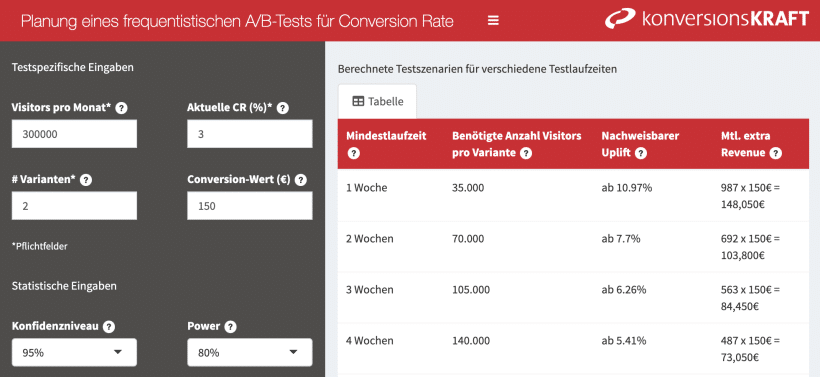
Zur Berechnung der Testdauer benötigt das Tool folgende Informationen von dir, welche du auf der linken Seite in die Felder eingibst:
- Visitors pro Monat – Die durchschnittliche monatliche Anzahl der Unique Visitors auf dem Seitentyp, der vertestet werden soll.
Planst du zum Beispiel einen Test auf der Produktdetailseite, so verwendet man hier die Anzahl der unique Visitors pro Monat, die die Produktdetailseite besucht haben.
Wir empfehlen hier einen Durchschnittswert über mehrere Monate in der Berechnung zu bilden, um Einflüsse von Werbekampagnen oder saisonale Schwankungen abzufangen.
- Aktuelle Conversion Rate (in %) – Der Anteil der Visitors auf dem Seitentyp, der vertestet werden soll, mit mindestens einer Conversion an allen Visitors auf dem Seitentyp.
Wichtig ist, dass sich die Conversion Rate auf die Visitors bezieht, die die zu vertestende Seite besucht haben. Für den Test auf der Produktdetailseite verwendest du dann die Conversion Rate der Besucher, die überhaupt eine Produktdetailseite besucht haben (Tipp: Für die Berechnung empfehlen wir, ein entsprechendes Segment im Web Analytics Tool anzulegen, in dem die relevante Besucherbasis für den Seitentyp erfasst wird).
Auch hier empfehlen wir, Werte über mehrere Monate zu einer durchschnittlichen Conversion Rate zu aggregieren.
- Die Anzahl der Varianten – Das ist die Anzahl der Varianten (inklusive Control), die vertestet werden sollen.
- Die Eingaben zum Konfidenzlevel und Power sind standardmäßig zur Berechnung auf 95 % für das Konfidenzlevel und 80% für die Power eingestellt. Du kannst diese natürlich trotzdem anpassen wenn du andere Werte verwenden möchtest.
Anmerkung: Die Berechnungen zur benötigten Testlaufzeit basieren auf einem einseitigen Hypothesentest.
- Das Feld Conversion-Wert in EUR ist ein optionales Feld, das dir helfen soll, eine bessere Einschätzung des zu erwartenden Uplifts vorzunehmen und deinen Test besser priorisieren zu können. Es zeigt dir, welchen zusätzlichen Umsatz das Testkonzept auf Basis deiner Eingaben und eines bestimmten Uplifts generiert, wenn du das erfolgreiche Testkonzept ausrollen würdest.
Das Feld musst du nicht zwingend ausfüllen um eine Testdauerschätzung durchführen zu können.
Wir haben mehrere statistische Tools entwickelt, die uns tagtäglich dabei unterstützen zahlreiche A/B-Tests richtig zu planen und valide auszuwerten. Wir teilen gern unsere Schatzkiste mit dir, die deinen Optimierer-Alltag erleichtern wird und dabei hilft, vertrauensvolle Ergebnisse zu liefern.
A/B-Testing mit dem Sample Size Tool richtig interpretieren
Wie dir sicher schon aufgefallen ist, benötigt das Tool keine Eingabe von dir, welchen Uplift du eigentlich aus dem Test erwartest, obwohl dies doch eigentlich eine relevante Einflussgröße aus die Testlaufzeit ist. In vielen online verfügbaren Tools wird dieser Wert als Input vom Nutzer gefordert um eine Testdauerberechnung durchführen zu können.
Wir möchten dir diese schwierige Einschätzung ein Stück weit abnehmen, indem das Tool dir in der Ausgabemaske rechts unterschiedliche Testdauerschätzungen für unterschiedliche Uplift-Szenarien anzeigt.
Die dargestellten Uplifts bezeichnen den minimal nachweisbaren Uplift (MDE = Minimum detectable Effekt) auf Basis deiner Eingaben. Er gibt an, welchen Uplift du nachweisen kannst, wenn der Test zum Beispiel 1, 2 oder 3 Wochen laufen kann. Andersherum: Für unterschiedliche Uplifts die du nachweisen möchtest, wird die entsprechende benötigte Testlaufzeit (in vollen Wochen) bestimmt.
Leider können wir dir damit die Einschätzung, wie hoch dieser nachweisbare Uplift denn nun eigentlich ist, nicht ganz abnehmen. Folgende zwei Fragestellungen können dir aber bei der Schätzung helfen:
1. Welche Uplifts sind realistisch?
Das Tool gibt dir die Möglichkeit, unterschiedliche Uplift-Szenarien durchzurechnen: Was wäre ein Best-Case und was ein Worst-Case-Szenario?
Wir empfehlen dabei, den Uplift, den man erzielen kann, eher konservativer einzuschätzen um sicherzugehen, dass die Testdauer auch sicher ausreicht, wenn er doch etwas geringer ausfällt als du hoffst.
Oft ist es auch so, dass die Testdauer die man zur Verfügung hat, der begrenzende Faktor ist. Aussagen wie: “Wir müssen in 2 Wochen Ergebnisse haben” hat wahrscheinlich jeder Optimierer schon einmal gehört.
Durch diese Betrachtungsweise in unserem Tool, bekommt man eine bessere Einschätzung, ob der Uplift, den man in zwei Wochen statistisch nachweisen kann, mit dem Testkonzept überhaupt realistisch zu erreichen ist. Mit einer sauberen Testdauerberechnung hat man eine gute Argumentationsgrundlage, um den Zeitraum zu verlängern, das Konzept zu überarbeiten oder sogar ein anderes, erfolgsversprechenderes Konzept in der Priorisierung vorzuziehen.
2. Wann ist ein Uplift im A/B-Test überhaupt Business relevant?
Der minimal nachweisbare Uplift ist derjenige Uplift, den man auf Basis einer bestimmten Testdauer mindestens nachweisen möchte, um a) ein statistisch valides Ergebnis zu erzielen und b) zu zeigen, dass der Test ein Erfolg gewesen ist und man das Konzept nun ausrollen würde.
Abgesehen von der statistischen Validität; ab wann würde man eigentlich sagen, dass ein Test aus Business Sicht erfolgreich war?
Dafür ist es hilfreich, im Vorfeld eine Kosten-Nutzen-Betrachtung im Rahmen der Testplanung einfließen zu lassen und sich die Frage zu stellen: Welchen zusätzlichen Umsatz müsste das Konzept eigentlich erzielen, um die Kosten der Implementierung mindestens zu decken oder im besten Fall darüber hinaus signifikanten Gewinnzuwachs zu generieren?
Wenn du dich schon einmal mit dem Thema ROI – Berechnungen von A/B Tests beschäftigt hast, weißt du vielleicht, dass es methodisch schwierig ist, den Wert eines Uplifts aus einem A/B Test in die Zukunft zu prognostizieren.
Um aber überhaupt eine Schätzung des Umsatzwertes vornehmen zu können, wählen wir in diesem Rahmen einen pragmatischen Ansatz:
Zum Einen werden dir im Tool die zusätzlichen Conversions angezeigt, die du auf Basis eines bestimmten Uplifts pro Monat erzielst, wenn das Testkonzept ausgerollt werden würde (Der Einfachheit halber werden hier keine Gewöhnungseffekte in Form von “Abschreibungsfaktoren” inkludiert, die den Uplift über die Zeit hinweg schmälern).
Wenn du zusätzlich im Tool die optionale Angabe machst, wie hoch der Wert einer Conversion (in EUR) auf deiner Website aktuell ist (auf Basis einer monatlichen Durchschnittsbetrachtung), bekommst du im Ausgabefenster Informationen zur monetären Bewertung des Uplifts.
Für unterschiedliche Uplift Szenarien wird dir angezeigt, welchen zusätzlichen Umsatz du erzielen würdest, wenn ein bestimmter Uplift eintritt und das Konzept auf alle Nutzer ausgerollt werden würde (auch hier gelten die vereinfachten ROI-Berechnungsregeln).
Die zusätzlichen Conversions bzw. der zusätzliche Revenue dienen als Hilfestellung dafür, Kosten-Nutzen-Betrachtungen bereits bei der Testplanung einzubeziehen und eine vereinfachte ROI-Betrachtung durchzuführen. Indem die Business Relevanz schon in die Test-Roadmap-Planung mit einfließt, lassen sich Tests besser priorisieren.
Unser Tool kann dir durch diese Betrachtungsweise helfen, wichtige Fragen bei der Testplanung besser einzuschätzen und zu beantworten. Die Entscheidung, welche Uplifts wirklich realistisch sind, können wir damit final nicht genau beantworten. A/B Testing ist letztendlich die Anwendung des Konzepts “Lernen, Validieren und Anpassen”. Das gilt auch bei der Testplanung. Je mehr Erfahrung man hierbei sammelt, desto hochwertiger werden die Tests.
„Es ist besser, unvollkommene Entscheidungen durchzuführen, als beständig nach vollkommenen Entscheidungen zu suchen, die es niemals geben wird.”
– Charles de Gaulle
5 Schritte für eine erfolgreiche Testplanung
- Gehe unterschiedliche Uplift-Szenarien durch und versuche so gut es geht eine realistische Einschätzung vorzunehmen. Plane besser konservativ als zu positiv.
- Definiere für dich, wie viel Uplift deine Variante mindestens erreichen muss, damit du von einem erfolgreichen Test sprichst.
- Eine Kosten-Nutzen Analyse hilft dir dabei herauszufinden, ab welchem Uplift ein Test wirklich erfolgreich ist.
- Berechne die Mindestlaufzeit und behalte diese fest im Auge.
- Schalte den Test erst ab, wenn du die Mindestlaufzeit erreicht hast.












3 Kommentare
Inga,
Guter Artikel, aber allmählich wiederholen sich Ihre Themen hier im Blog immer öfter. Das war hier ja schon öfters Thema
Julia Lehwald,
Hallo Inga, danke für dein Feedback! Welche Themen würdest du dir noch wünschen für die Zukunft? Wir berücksichtigen das gern in unserer Themenplanung! Liebe Grüße
Axel Schröder,
Hallo Frau Engelmann,
ich würde mich freuen, wenn der Artikel um Ausführungen zur Abschätzung von Testlaufzeiten / statistischen Power bei Verwendung des Bayesschen Ansatzes (wie z.B. bei Google Optimize) ergänzt werden würde.
Vor allem hat nicht jeder den Traffic der großen Portale, sondern ist froh, wenn er in annehmbarer Zeit 100 Conversions je Variante zusammenbringt.