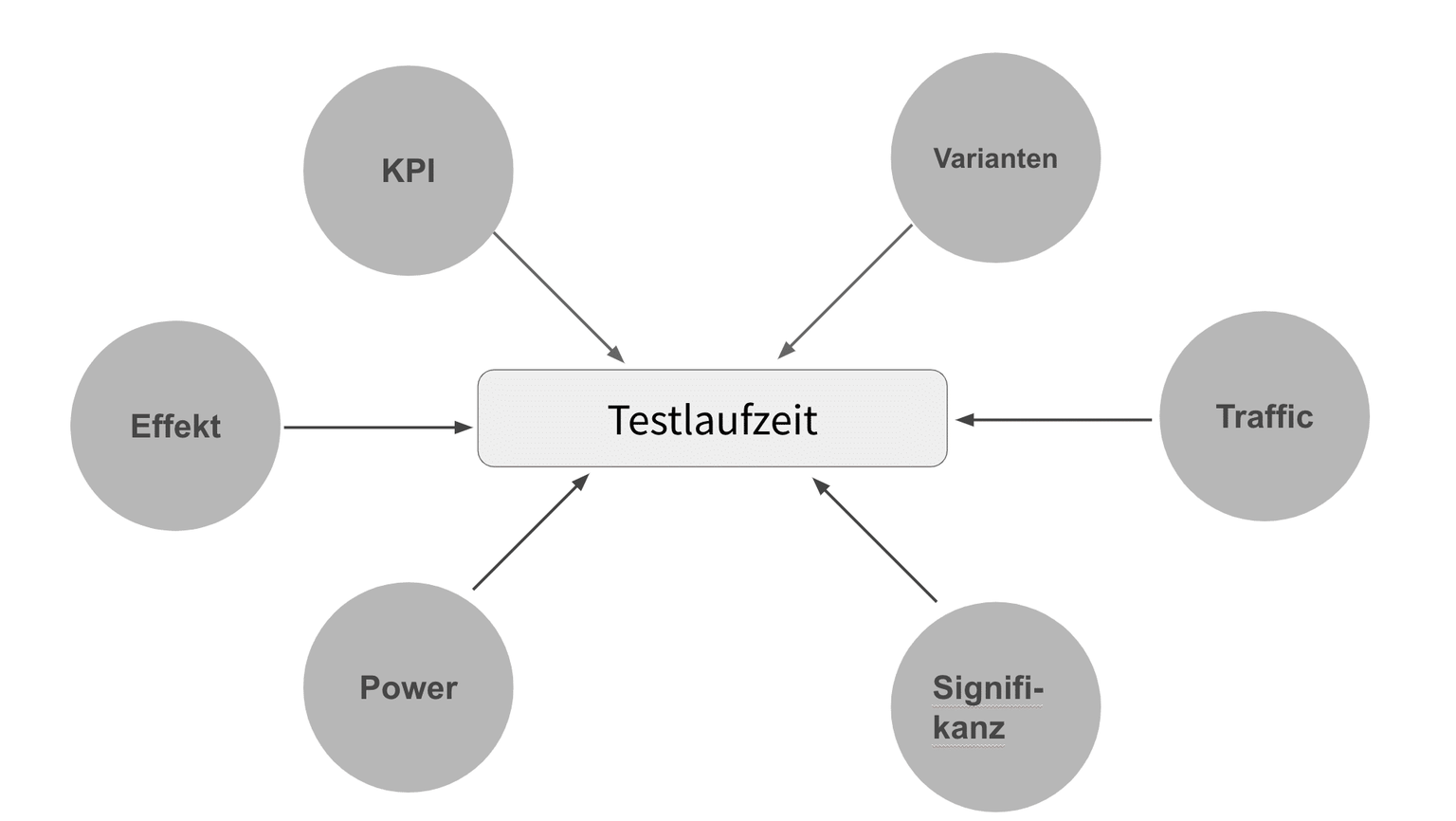
Die Anzahl an Nutzern und deren Conversion Rate, die in einem A/B-Test teilnehmen sollen, können sich je nach Testkonzept sehr stark unterscheiden. Ein Test auf der PDP wird in einer Woche von deutlich mehr Nutzern gesehen als einer im Warenkorb, wogegen dort die Conversion Rate nicht unerheblich höher liegen wird.
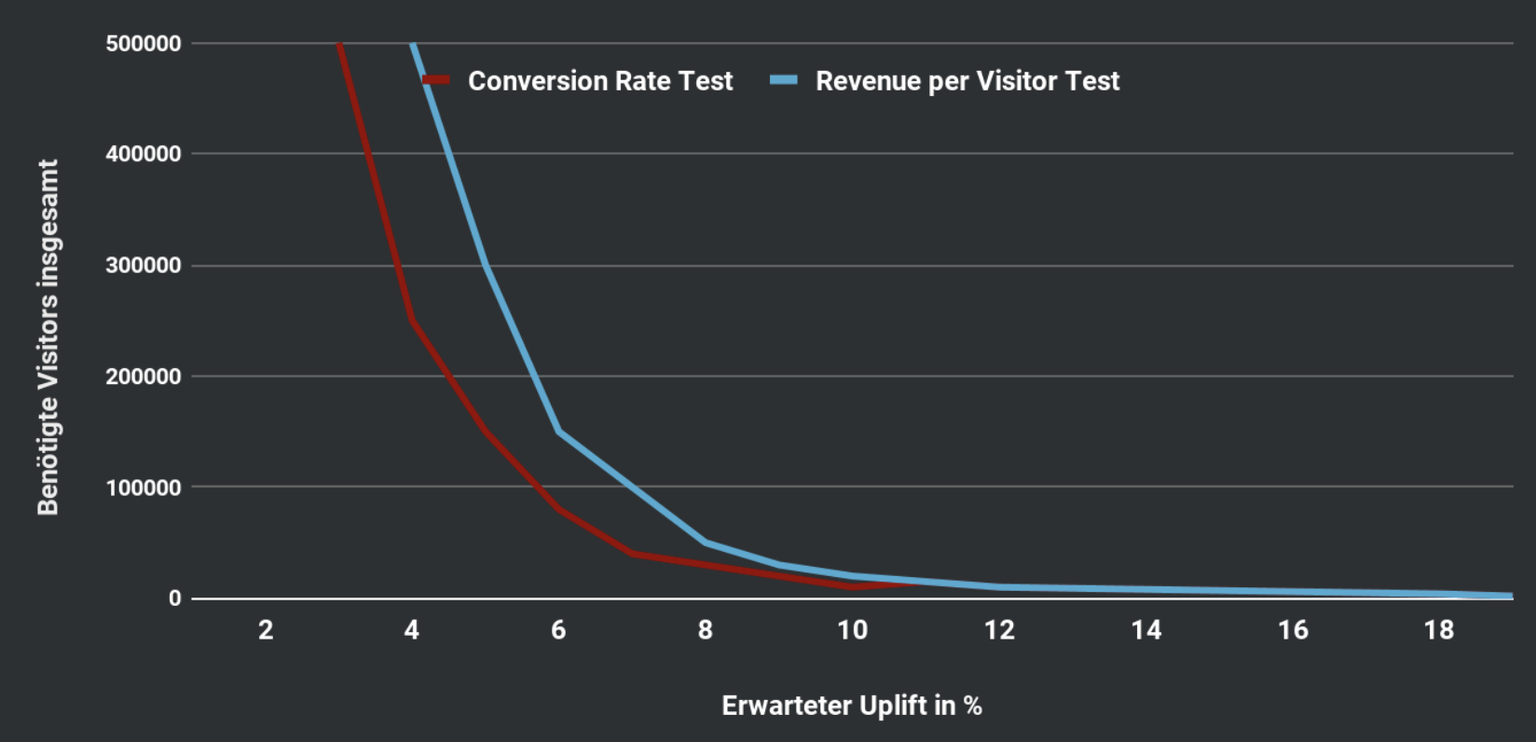
Zudem wird dabei nicht berücksichtigt, dass von unterschiedlichen Testkonzepten auch diverse Effekte (Uplifts) erwartet werden. Die einfache Regel lautet: Um große Effekte erkennen zu können, reichen in der Regel kleinere Stichproben. Für kleine Effekte braucht man eine größere Stichprobe.
Ist die pauschale Testlaufzeit also zu klein für den Effekt, der von einer Variante stammen kann, tappen wir vermutlich in die False-Negative-Falle, also ein nicht-signifikantes Ergebnis, obwohl die Variante in Wahrheit ein Gewinner war.
Die Wahrscheinlichkeit beider Fehlerarten – False-Positives (Alpha-Fehler) und False-Negatives (Beta-Fehler) – versucht man im A/B-Test zu begrenzen. Dafür fixiert man das Konfidenznievau zur Begrenzung des Alpha-Fehlers und die Test-Power für die Kontrolle des Beta-Fehlers.
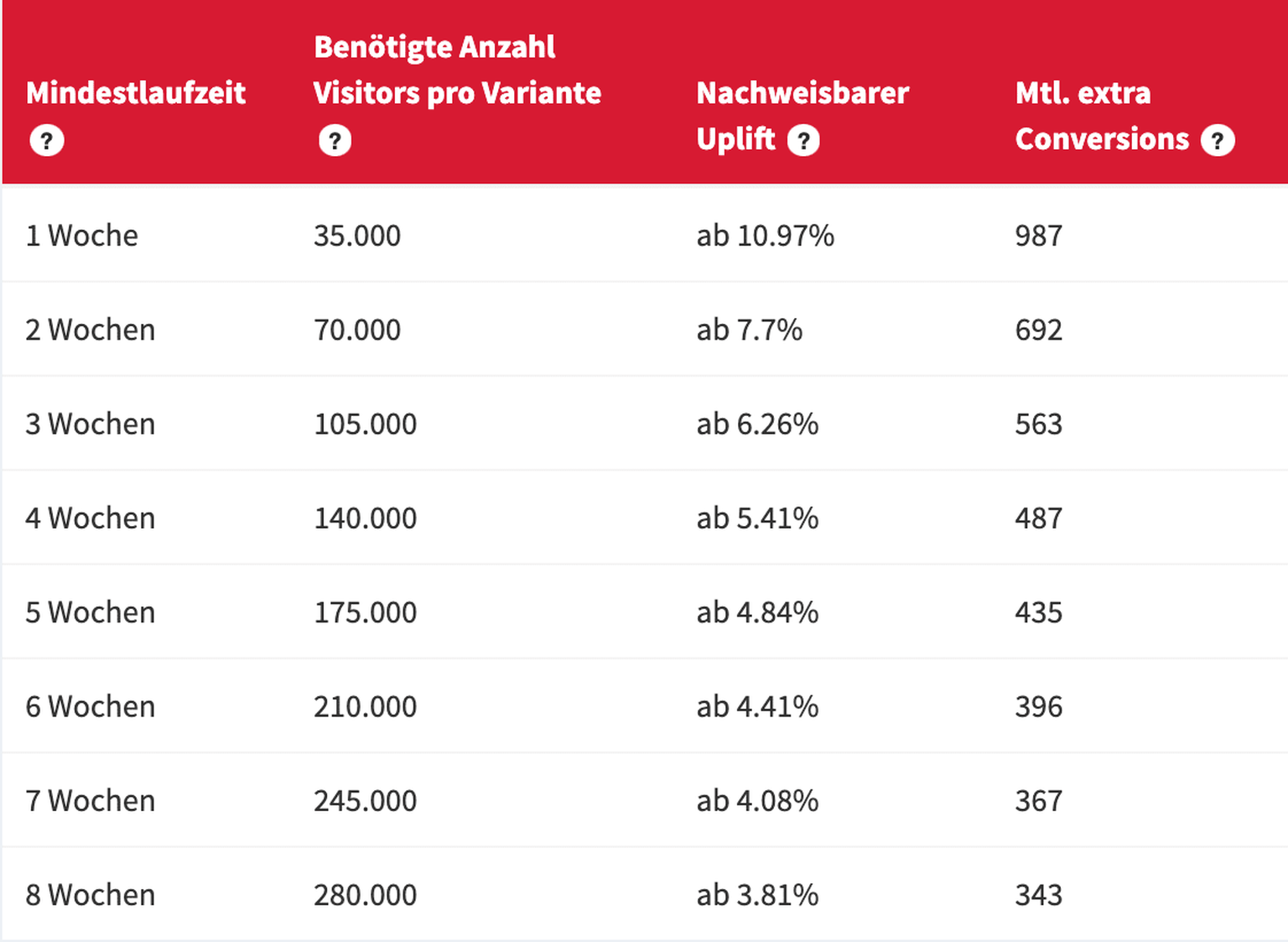
Wenn diese Parameter fix sein sollen (Traffic und Conversion Rate sind ebenfalls fix durch das Testkonzept definiert), muss man die Sample Size dementsprechend für jeden Test individuell anpassen.